
Machine Learning in der Produktion ist komplex, lässt sich aber mit dem richtigen Setup sehr gut automatisieren. Dieser Artikel zeigt beispielhaft auf, wie ein vollautomatisches ML-System aufgebaut werden kann, das sich kontinuierlich selbst verbessert.
Die Herausforderung
Stellen Sie sich vor: Sie haben tausende Bilder und möchten ein KI-Modell trainieren, das diese Bilder klassifiziert. Die klassische Herangehensweise bedeutet oft:
- Daten manuell in Ordnerstrukturen sortieren
- Skripte für Training schreiben und manuell ausführen
- Modelle manuell deployen
- Bei neuen Daten: Alles von vorne
Das kann Wochen dauern und ist fehleranfällig und bedeutet enormen manuellen Aufwand.
Die Lösung: Ein selbstlernendes Machine-Learning-Ökosystem
Statt isolierter Komponenten sollte ein integriertes System aufgebaut werden, bei dem alle Teile nahtlos zusammenarbeiten, um die manuellen Aufwände auf ein Minimum zu reduzieren. In unserem Beispiel-Setup sieht das wie folgt aus:

Die Komponenten im Detail
Label Studio: Das Herzstück der Annotation
ML-Backend: Der Vermittler
MLflow: Die Model-Registry
Version 1: 100 Annotations → Accuracy 75%Version 2: 500 Annotations → Accuracy 89%Version 3: 1.000 Annotations → Accuracy 94%Forgejo CI/CD: Die Trainings-Infrastruktur
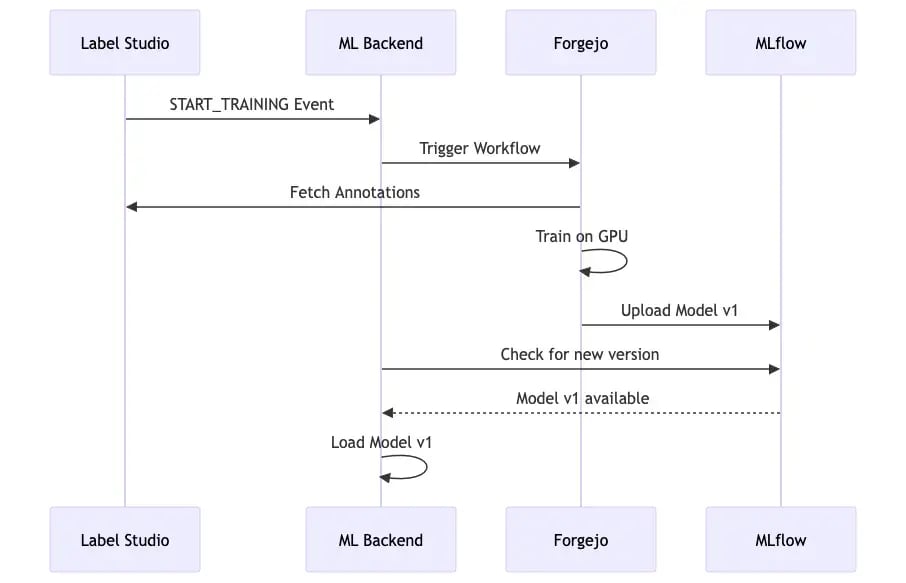
Der Workflow
.github/├── workflows/ ├── train.yaml # workflow file for the training pipeline ├── deploy_backend.yaml # workflow file for ml-backend deployment ├── ...models/├── cats_and_dogs_classifier/ # all files in this folder are created with create_new_model.py ├── backend.py # ml-backend Implementation for the cats_and_dogs_classifier ├── config.yaml # configuration for this backend ├── docker-compose.yaml # deployment config for ml-backend (extends ../../src/predict/docker-compose.yaml) ├── labeling_template.xml # labeling template for label-studio ├── model.py # model-architecture (z.B. MobileNetV2)├── ... # More backend and model definitions... ├── ...├── template/ # template files for each model type ├── classification/ ├── common/ ├── detection/scripts/├── create_new_model.py # generates the whole project structure for a new model under models/├── upload_images_to_s3.py # helper script for simple upload of new image assets├── setup_label_studio_project.py # creates a new project in label-studio├── ... # more scripts... src/├── common/ # shared code between predict and train├──train/ ├── Dockerfile ├── docker-compose.yaml # deployment config for training container running the training workflow ├── *.py # base classes for Label Studio ML Backends├── predict/ ├── Dockerfile ├── docker-compose.yaml # base deployment config for ml-backend container running the predictions ├── *.py # base classes for model trainingPhase 1: Setup für ein neues Modell
Ein Developer erstellt die Modell-Struktur im Git-Repository. Anstatt alle Dateien manuell anzulegen, nutzten wir dabei ein Template-System über welches alle Dateien generiert werden:
python scripts/create_new_model.py \ --model cat_and_dog_classifier \ --problem-type classification \ --classes "Cat,Dog" \ --architecture pretrainedmodels/cats_and_dogs_classifier/ ├── model.py # Modell-Architektur (z.B. MobileNetV2) ├── backend.py # ML Backend Implementation ├── config.yaml # Konfiguration (Single Source of Truth) └── docker-compose.yaml # Deployment Configconfig.yaml ist dabei das Herzstück: Sie definiert nicht nur Hyperparameter, sondern auch die Label Studio Integration, S3-Pfade, Modell-Architektur und sogar die Labeling-Templates. Alles an einem Ort und versioniert in Git.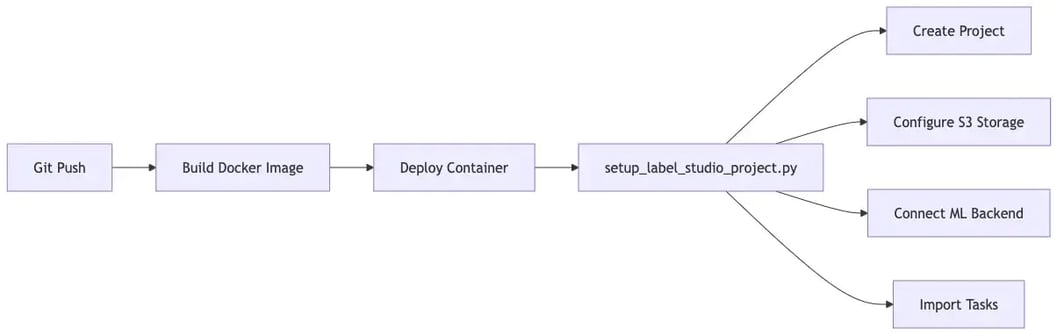
setup_label_studio_project.py Script liest dabei die config.yaml und konfiguriert automatisch:Phase 2: Erste Annotationen
Phase 3: Erstes Training
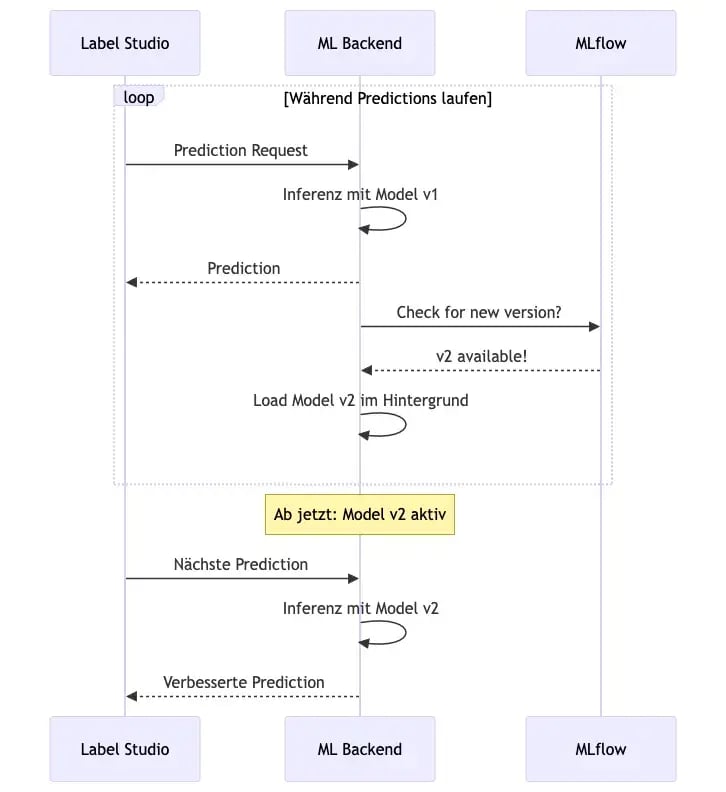
Der kontinuierliche Verbesserungszyklus
Die Prediction-Loop
Der Retraining-Loop
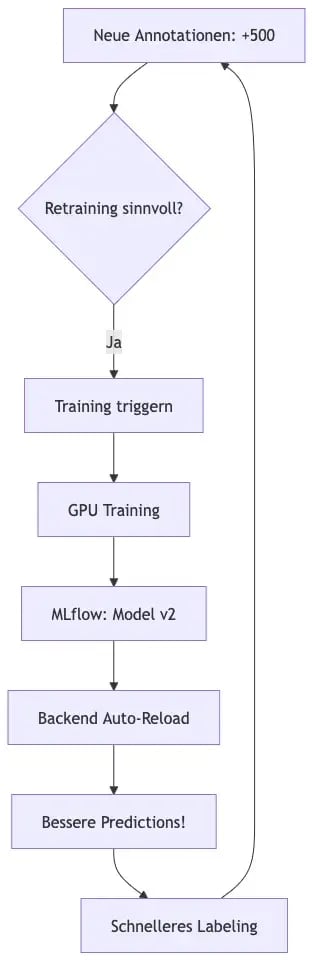
Fazit
Kontaktieren Sie uns – wir würden uns freuen Sie bei diesem Weg zu begleiten!